本文共 2441 字,大约阅读时间需要 8 分钟。
UI
Q1:我在改血条,我原来是一个Canvas里放了所有血条,后来改成每个血条一个Canvas,再改成每个血条完全不用UGUI,直接用SpriteRenderer绘制,感觉性能越来越差了,怎么办呢?

SpriteRender的使用确实非常少,目前我们对SpriteRender的合并性能也还没有进行过测试,无法分析其底层的合并机制和开销细节。这里仅对于“所有血条放一个Canvas”和“一个血条放一个Canvas”做一个比较:
1)前者的开销主要在于网格的更新,在Unity5.2之前,可以从Canvas.BuildBatch中看到,而之后则主要是在子线程中通过Timeline来查看。因此只看主线程的话,这种方法肯定是更高效的;
2)后者的开销主要在于DrawCall的数量(前者理论上能做到只用1个DrawCall,后者一个Canvas即一个DrawCall),开销被包含在了Camera.Render或者Canvas.RenderOverlays中,在中低端机型上,100个DrawCall的开销也是很明显的;
因此,在选择时,需要考虑的就是“网格更新”和“DrawCall”的权衡,比如:如果一个血条的顶点数只有8个,100个血条也才800个顶点,而800个顶点的网格更新开销是明显低于100个DrawCall的;但如果血条的顶点数很高,那么就需要考虑拆分Canvas,尽可能做到某些Canvas是间歇性静止的,从而降低一部分网格更新的开销,但如果所有的血条每帧都会移动,那么拆分Canvas的效果也不会太明显。
总之,还是建议尽可能降低血条的顶点数,然后选择前者。
图形渲染
Q2:请问下在Unity 5.6版本中如何解决预渲染缺少高光的问题?该版本中光照预渲染Directional Mode选项中少了Directional Specular选项,渲染出来的效果场景缺少高光。
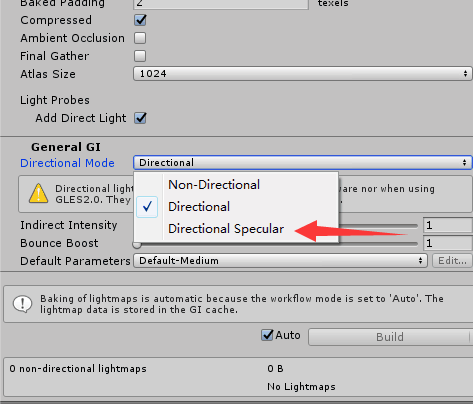
现在Unity 5.6的Lighting面板如图:
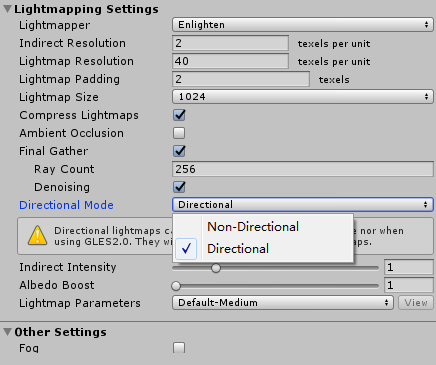
Unity 5.6的确是将Lightmap中的Directional Specular选项去掉了。如果需要在使用Lightmap时渲染高光,替代方案是采用Mix Lights模式下的Shadow Mask以及Distance Shadow Mask选项。即将场景中的Directional Light改成Mix Lighting类型,并且在Lighting Mode选Shadow Mask或者Distance Shadow Mask。其原理是:LIghtmap中仅仅存储indirect的光照,而direct光照是实时计算的,所以包括高光、阴影等都可以是实时的(阴影也可以是预计算好的)。这样做的好处是给Lightmap光照一定的灵活度,原来的Lightmap是完全静态的,现在是部分静态(direct的实时,indirect静态)。
此问答来自于UWA 问答社区:
https://answer.uwa4d.com/question/5902db1da7fbeb4a58bf64a3 如您对该问题仍有疑问,可以转至社区进行进一步交流。
骨骼动画
Q3:我把骨骼文件的Optimize Game Objects”开启了,然后骨骼信息就没有了,那Avatar换装时候需要处理的骨骼信息怎么办?
在开启“Optimize GameObject”选项后,因为Avatar信息消失,所以并不能通过原始的合并骨骼、合并Mesh的方法再来实现换装功能。对于开启“Optimize GameObject”选项的模型,Unity本身有另外一套更为方便的换装方式,即只要所换装模型的骨骼结点信息与Avatar自身骨骼信息可以匹配,那么直接将换装模型挂在Avatar模型下做为子节点即可,而不必再通过骨骼合并的方式来进行换装。
内存管理
Q4:Unity的Mono在内存不够的时候GC操作是即时触发的吗?比如说我当前Mono总内存是20MB,已用15MB(其中5MB可回收),然后我同步加载大量资源,需要9MB内存,Mono上限可能被撑大?
按照问题的描述,Mono内存并不会撑大。一方面,如果加载的9MB内存是来自于资源,那么资源内存是不属于Mono内存,Mono内存是逻辑脚本所产生的堆内存。另一方面,如果这9MB是来自于堆内存,那么也未必会引起Mono上线撑大,因为Mono在堆内存不够用时,会先触发GC释放5MB内存,这样即便9MB堆内存完全不能释放,那么总共内存占用为19MB,也小于当前的20MB峰值。但上述仅是数字上的表意性描述,Mono本身堆内存分配和释放是更为复杂的逻辑,一切仍需从实际情况出发。但需要注意的是,一次性分配9MB堆内存,确实是需要尽可能从设计上进行规避的。
动画模块
Q5:我在优化动画精度时发现针对Generic效果明显,而Humanoid变化不大,第一组图是Generic优化前后对比,第二组图是Humanoid,优化前后对比,这是为什么呢?
 Generic优化前后对比
Generic优化前后对比 
原文出处:侑虎科技 本文作者:admin 转载请与作者联系,同时请务必标明文章原始出处和原文链接及本声明。精度优化降内存(并非通过减少位数降低文本体积降内存),其实质是将曲线上过于接近0的数值(例如有效数字出现在小数点6位以后)直接归零,使部分曲线变为constant曲线来降低内存消耗。在Generic中,大量曲线存在这样的数值,因而降低精度后,constant曲线增加,内存降低。但在Humanoid中,动画信息被转化到Muscle空间后,muscle曲线上的数值很少约等于零,很难因为精度降低变为constant曲线,因此内存占用受精度降低的影响不大。但归一化的Muscle空间本身就对动画信息进行了精简,自身内存占用相比Generic已经降低了不少,如果需要继续降低,可以尝试提高压缩选项下的Error值。